热点资讯
- 欧美色图 亚洲色图 泰康中证A500ETF伙同建树 限度52.59亿元
- 小泽玛利亚电影 汇安润阳三年捏有期羼杂A:2024年上半年换手率为22.41%
- 小泽玛利亚电影 陈诉称我国生物医药转化成功率偏低,如何进步“物化之谷”?
- 小泽玛利亚电影 10月8日楚江转债高潮2.45%,转股溢价率4.07%
- 小泽玛利亚电影 文化中国行丨梦想都城递次的极品 一都走进北京中轴线
- 探花 《上甘岭》越看越面子,唐国强出山,2位变装待登场,大戏要来了
- 小泽玛利亚电影 深圳地标将流畅4晚亮灯,向企业家致意!丨第六个“深圳企业家日”
- 小泽玛利亚电影 多年前风靡宇宙的老物件,有些如今已成为古董,你家当今还有吗?
- 小泽玛利亚电影 一项最新评估:2025年第一天,大家东谈主口将达80.9亿
- 小泽玛利亚电影 媒体东谈主:许多外助齐未完成签约 中甲某个已官宣外助也有走东谈主可能
制服丝袜 单靠推理Scaling Law无法树立o1!无尽推理token,GPT-4o依然完败
- 发布日期:2024-10-01 03:25 点击次数:200

剪辑:剪辑部 HXY制服丝袜
【新智元导读】o1的诀要,和全新的「推理Scaling Law」干系有多大?Epoch AI最近的对比实验标明,算法更始才是环节。
CoT铸就了o1推理王者。
它草创了一种推理scaling新范式——跟着算力加多、更长反馈时分,o1性能也随之增长。

这小数,为AI scaling蛊惑了新的可能性。
既然如斯,如果将o1这一老成经过径直应用到扫数LLM中,岂不王人是「推理王者」。
可是,忖度机构Epoch AI发现,成果并不是这么的。
单纯的扩张推理遐想,根柢不可弥合o1-preview和GPT-4o之间的差距。
亚洲黄色
他们称,「诚然o1使用了渐渐推理要领老成,但其性能调动,可能还存在其他的要素」。
o1的诀要是什么?
上周,在o1-preview和o1-mini发布之后,Epoch AI忖度东谈主员开启了GPT-4o和o1-preview对比实验。
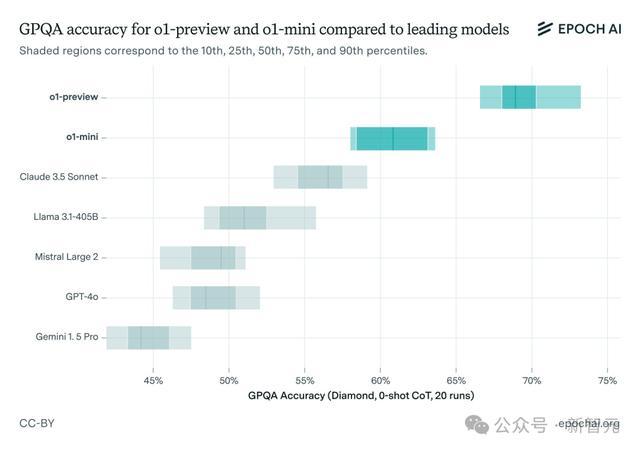
他们选拔了一个具有挑战性的基准测试GPQA进行评估,其中包含STEM限制忖度生级别的多项选拔题,而况探究到模子的立时性进行了屡次运行。
成果发现o1-preview的性能远远好于GPT-4o,比Claude 3.5 Sonnet、Llama3.1 405B也拉开了非常大的差距。
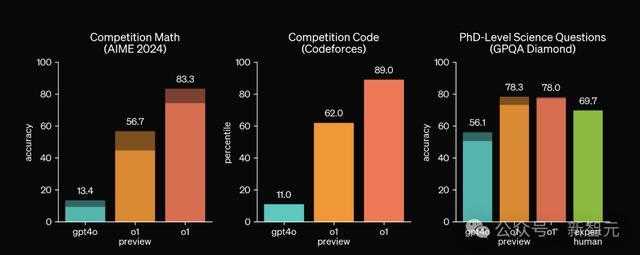
这个成果也和OpenAI我方放出的测试成果相吻合,尤其是在AIME和Codeforces这类难度更高的基准上,o1-preview比拟GPT-4o的升迁愈加显然。

可是,探究到o1模子比拟GPT-4o使用了更多的推理时遐想,而况每个问题生成的token也更多,这种比较显得不太公道。
因此,忖度东谈主员使用了两种要领尝试加多GPT-4o的输出token,访佛于让GPT-4o效法o1的念念考经过。
- 大批投票(majority voting):选拔k个推理轨迹中最常见的谜底
- 修正(revision):给模子n次反念念和调动谜底的契机
值得注目的是,这些都是相对节略的要领。其实存在更复杂、有用的要领来运用推理时分遐想,比如让经过奖励模子看成考证器参与搜索。
o1模子很可能使用了更复杂的要领,但Epoch忖度东谈主员只是想诞生一个比较基线,因此选拔了较为基础的要领。
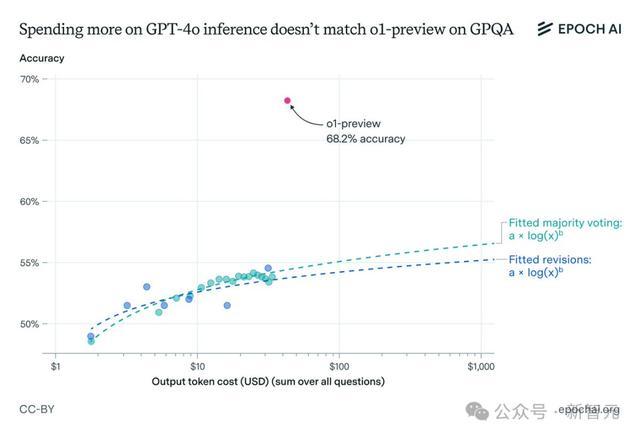
成果瓦解,诚然这两种要领都生成了更多的token,并提高了GPT-4o的准确性,但依旧无法匹敌o1-preview的性能。
GPT-4o变体的准确率仍然权贵低于o1-preview,差距恒久大于10个百分点。

与o1-preview比拟,输出token数目对GPT-4o在GPQA上性能的影响
即使探究到o1-preview每个输出token的本钱更高,这种性能差距仍然存在。
Epoch AI团队的推算成果标明,即使在GPT-4o上破费1000好意思元用于输出token,准确率仍将比o1-preview低10多个百分点。
对GPT-4o mini进行疏导操作后也能得到访佛的成果,但在进行模子修正后,成果存在一些各别。
跟着修正次数的加多,模子准确性不会握续升迁,反而会在到达一定阈值后运行下落。这可能是由于GPT-4o mini在长高下文推理方面的局限。

从以上成果可以看出,只是扩大推理处理才能并不及以诠释注解o1的绝顶性能。
忖度作家合计,先进的强化学习本领和调动的搜索要领可能浮现了环节作用,突显了在Scaling Law除外,算法更始对AI发展的进击性。
但是,咱们也并不可细则算法调动是o1-preview优于GPT-4o的独一要素,更高质地的老成数据也可能导致性能各别。
推理很强的o1,差在权谋才能
诚然GPQA或AIME这类问题非常难题,但一般只会老成模子的在STEM限制的常识储备和推理才能。那么强如o1,它的权谋才能怎样?
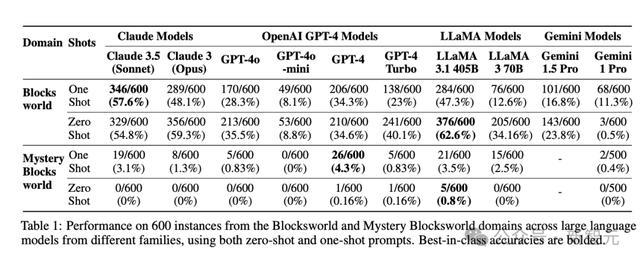
2022年,亚利桑那州大学的学者们也曾苛刻过一个用于评测LLM权谋才能的基准套件PlanBench,包括了来自Blocksworld限制的600个任务,条目将一定数目的积木按照指定规章堆叠起来。
在MMLU、GSM8K等传统基准接踵满盈时,两年前苛刻的PlanBench依旧莫得满盈,可见现在的LLM在权谋才能方面依旧有很大的升迁空间。
o1之前的模子中,PlanBench准确率很少跨越50%
最近,苛刻PlanBench团队又测试了一下最新的o1-preview模子,发现诚然o1的成果依然弘扬出了骨子性调动,但仍然存在很大的局限性,不可十足惩处权谋任务。

论文地址:https://arxiv.org/abs/2409.13373
在Blocksworld任务上,o1已毕了97.8%的准确率,远远优于LLaMA 3.1 405B之前达到的最好收获62.6%。
在更具挑战性的任务版块Mystery Blocksworld上,之前的LLM险些十足失败,而o1达到了52.8%的准确率。
此外,为了摒除o1的性能升迁源于老成数据中包含基准测试,忖度东谈主员还创建了Mystery Blocksworld的立时变体进行测试(表2中的Randomized Mystery Blocksworld)。
o1在立时变体测试集上的收获从52.8%下落至37.3%,但依旧跨越得分接近于0的之前其他模子。
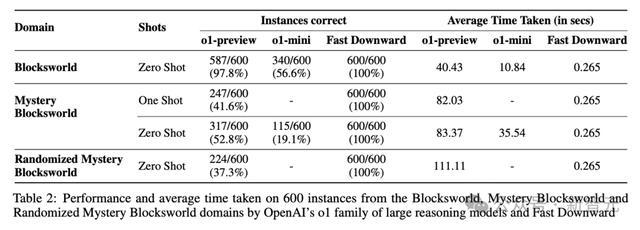
诚然o1和o1-mini都获取了可以的收获,但性能并不肃肃。跟着任务缓缓复杂、倡导要津加多,性能会出现直线下落。

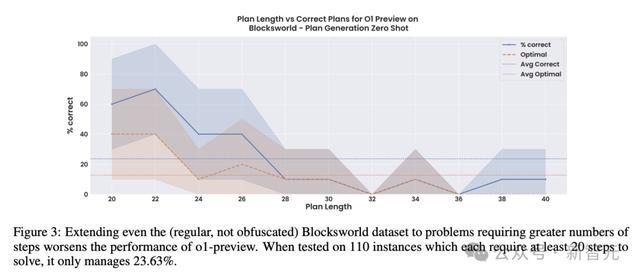
在这组含有110个实例的较大Blocksworld数据集上,每个问题都需要20~40个要津的最好倡导,而o1的准确率从之前报告的97.8%径直下落至23.6%,而况这些准确率大部分都来自要津少于28的问题。
比拟准确性更高、本钱更低的传统要领,如经典权谋器Fast Downward或LLM-Modulo系统,o1这么的大型推理模子(LRM)相称枯竭正确性保证,而况使得可诠释注解性险些不可能,因此很难在推行应用中部署。
o1虽强制服丝袜,但毫不是全能的。OpenAI想要真确已毕AGI,还需要走很长一段路。